Ming Tommy Tang
Director of Bioinformatics
About me

Ming “Tommy” Tang is the Director of Bioinformatics at AstraZeneca with 14+ years of experience in computational biology, single-cell genomics, and cancer research. He is the author of the Chatomics blog (230+ tutorials, 6,000+ monthly readers) covering single-cell RNA-seq, Seurat, R/Python programming, ATAC-seq, and bioinformatics best practices. He holds a PhD in Genetics and Genomics from the University of Florida.
Key Facts
- Current Role: Director of Bioinformatics, AstraZeneca
- Advisory Boards: Pythia Biosciences (Scientific Advisory Board), Northeastern University Bioinformatics Program (Industry Advisory Board)
- Education: PhD in Genetics and Genomics (University of Florida), BS in Biotechnology (Shanghai Jiaotong University)
- Blog: Chatomics — 230+ posts, 6,000+ monthly readers
- YouTube: chatomics — bioinformatics tutorials and tips
- Social Media: 120K+ followers across platforms, 30M+ impressions per year
- Speaking: 50+ talks at Stanford, EMBL, 10x Genomics, Festival of Genomics, and more
- Publications: Google Scholar
- Book: From Cell Line to Command Line
What I Write About
- Single-cell genomics: scRNA-seq analysis, Seurat tutorials, Scanpy, cell type annotation, data integration, CITE-seq
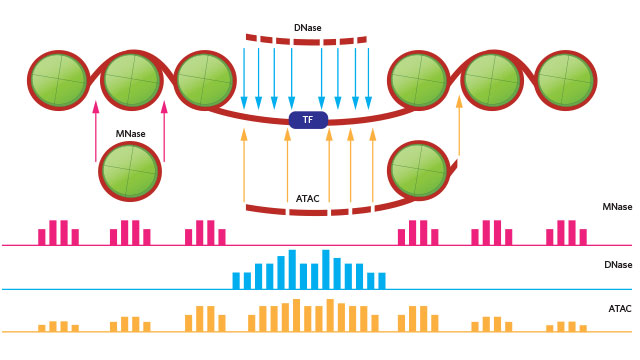
- Epigenomics: ATAC-seq, ChIP-seq, DNA methylation analysis
- Bioinformatics programming: R/Bioconductor, Python, Unix/shell scripting, Snakemake workflows
- Data science for genomics: Differential expression (DESeq2), visualization, machine learning, deep learning
- Reproducible research: Docker, version control, workflow management, open science
- Career development: Bioinformatics career advice, transitioning from academia to industry
I am a computational biologist working on genomics, epigenomics and transcriptomics. I use R primarily for data wrangling and visualization in the tidyverse ecosystem; I use Python for writing Snakemake workflows and reformatting data; I am a Unix geek learning shell tricks almost every month; I care about reproducible research and open science.
I also have a great interest in promoting open science and reforming bioinformatics education. I frequently share my thoughts on X (formerly Twitter) and tips on this blog. I am a certified instructor for the Carpentries.
I also have a YouTube channel chatomics where I share bioinformatics tips and tutorials.
Grab my book to transform yourself into a computational biologist.

My back story
Holding my passport in my hand, I was waiting in the long line at the US customs and immigration Seattle-Tacoma International Airport. My first day in the United States of America officially began. Also, this trip was my maiden voyage on an airplane.
I realized it’d been 14 hours, and it was still the same day as I departed: August 8th, 2008, the same day as the Beijing Olympic Games started. The rumbling noise of the jet engines was still somewhat lingering in my ears.
As the line slowly moved forward, I saw a giant US flag in the port of entry. I told myself, America, here I come.
With $2,000 in my wallet, that’s my parent’s entire life savings in the hope that one day I will be the first Ph.D. in my family. My final destination is Gainesville, Florida, a town I have never heard of up until a year ago. It is in the part of the Sunshine State where there are no beaches, no theme parks, but swarmed with mosquitos and alligators.
I arrived at the University of Florida to pursue my Ph.D. in genetics and genomics. A new chapter of my life began. For me, it was like a child being thrown into a candy store. All of a sudden, I have access to a top-notch wet lab and tons of new things for me to learn. Every day I clock at least 10 hours in the lab, including many weekends, and I quickly became an expert in pipetting.
Four years into my Ph.D. I’ve already published two first-author papers in well-respected journals. I was very happy. Until one day, my adviser asked me to download a 2 GB TXT file to analyze a public dataset. I could not open it in excel or any other software I am familiar with. Suddenly I realized that I didn’t have data analysis skills. A bit of frustration was an understatement,
It was like a rabbit hole. I started stockpiling books to learn Unix, python, and R programming languages. I also took many online courses on edx, Coursera, and udacity. I took pride in being one of their first loyal customers before they became popular.
I couldn’t wait to get up early in the morning and dashed to my lab, starting to devour chapters upon chapters and key in the newly learned programming codes as if they were video games before my lab started.
And when the busy lab day was over, I dashed to my apartment to resume my learning on Coursera, watching videos, taking notes, and doing homework. It opened a whole new world for me. I took almost 40 courses in various subjects of statistics, programming, and computation in the first few years.
It was not easy. I was the only one on the floor to learn bioinformatics and had no one to turn to. I spent hours googling how-to and error messages. During that time, I started a blog and journaling the problems I encountered and how I solved them. I didn’t expect that it would become a vastly popular site for beginners in the field and attracts over 6000 traffic every month around the world.
I didn’t know this little side hobby of mine actually impacted a lot of people. I am a little embarrassed that my pen name for the blog is crazyhottommy. One time, when I was teaching a seminar at UC Davis, one student asked me a question, and I gave her my blog link.
She was shocked and asked me, wait a minute, are you saying you are the crazyhottommy? I am your biggest fan!
I could never dream of that one day, my strong interest in computation could catapult me to the world-renowned MD Anderson cancer center in Houston, Texas., for my postdoctoral training as a computational scientist.
To me, it was like a child being thrown into a candy store again, only bigger and more flavors this time. There, I had the opportunity to explore and experiment with the astronomical size of real cancer genomic datasets.
My quest to combine data science and cancer research later got me a job at Harvard, Dana-Farber Cancer Institute. I further crafted my skills to analyze single-cell genomics datasets and continued to accumulate immuno-oncology knowledge.
But I suddenly realized that my role had changed; my research was no longer a one-person job. I need to lead a team to complete our extensive research. Our data comes from four prestigious cancer centers, including MD Anderson, Dana-Farber, Mt. Sinai, and Stanford Medical Center. There’s a lot of coordination and communication involved. I realized that I need to grow and learn even faster to be able to lead.
I started my quest for workshops, books, and mentorships, and I started to deep dive into the art of personal development and how to lead. I also started participating in Toastmasters International to enhance my public speaking skills. 10 years after I started learning computation, I am very fortunate that I was later given a great opportunity to work at a promising startup, Immunitas, in Boston.
Looking back, that clueless international student at US Customs and Port of Entry, Seattle Tacoma International Airport, now become a director leading the computational biology cancer research. It was the curiosity, like the kid in the candy store, to science, truth and self-mastery that drove me here today.
I am forever grateful for this journey. I want to end with one of my favorite quotes from the late Steve Jobs in the commencement speech he gave at Stanford in 2005:
all the dots will be connected one day only when you look back but not look forward. Stay hungry, stay foolish.
My career trajectory
Being trained in a wet lab in the University of Florida during my PhD in Dr.Jianrong Lu’s lab has established my solid knowledge and skills in experimental molecular cancer biology. Self-teaching and postdoctoral training in Dr.Roel Verhaak’s lab has extended my bioinformatics skills in integrating analysis of TB size sequencing data sets. Verhaak lab is well known for studying genomic alterations of brain tumor by analyzing large panels of RNA-seq and DNA-seq data. I gained extensive experience in handling large-scale genomic data and pipelining workflows. I also gained intimate familiarities with public data sets such as ENCODE, TCGA and CCLE. I have put my analysis notes and snakemake pipelines for processing whole-exome, whole-genome DNAseq, RNAseq, single-cell RNAseq, ChIP-seq, ATACseq and RRBS data in my github repos.
Roel moved to Jackson lab for Genomics Medicine in October 2016. To apply my skills to translational lung cancer research, I joined Dr. Andrew Futreal and Dr.Jianjun Zhang’s lab shortly to study tumor heterogeneity in lung cancer by analyzing multi-region whole-exome sequencing data and DNA methylation array data. I have been working as a research scientist in MD Anderson at Kunal Rai’s lab studying cancer epigenomics.
I joined Harvard Faculty of Arts and Sciences informatics team on October 1, 2018 as a bioinformatics scientist working closely with Dr.Dulac lab to catalog and understand the diversity and function of cell types in the mouse brain using single-cell RNA-seq and other cutting edge techniques.
I joined Dana-Farber Cancer Institute as a senior scientist in March 2020 and later promoted to a Lead scientist. My focus was using genomics, (single-cell) transcriptomics and (single-cell) epigenomics to study Cancer Immunology and leading the bioinformatics team of seven people for the Cancer Immunologic Data Commons (CIDC) project.
From Nov, 2021 to Aug, 2024 I served as the Director of Computational Biology at Immunitas Therapeutics. At Immunitas, we employed a single cell sequencing platform to dissect the biology of immune cells in human tumors. Our focus on human samples allowed us to start with and stay closer to the most relevant and translatable biology for patients and accelerates the pace of our research.
Now, I am the director of Bioinformatics at AstraZeneca. I am also serving as the scientific advisory board member for Pythia Biosciences, a bioinformatics software company focusing on multi-omics data analysis and industry advisory board member for the Northeastern University Bioinformatics program.
My new north star is “bringing drugs to patients”.
Interests
- (Epi)genomics
- single-cell
- Education
- Machine learning
- Unix
- rstats
Education
-
PhD in Genetics and Genomics, 2014
University of Florida
-
BS in Biotechnology, 2008
Shanghai Jiaotong University